

robots.txt veb-saytın “root directory”də yerləşən və axtarış matoru botlarınna nələri etməli və etməməli olduqları ilə bağlı təlimatlar verən mətn-fayldır. Bu fayl ilk axtarış matoru developer-lərinin ortaq fikrə gəlmələri nəticəsində yaranmışdır. Hər hansı bir qurum tərəfindən təsdiqlənmiş rəsmi bit standart olmasına baxmayaraq, bütün böyük axtarış matorları bu faylın qaydalarına əməl edir.
robots.txt axtarış matoru botlarına hansının səhifənin “crawl” edilib indekslənməsini və ya hansının edilməməsini müəyyən edir. Nəticədə bu fayl veb-sayt idarəçilərinə botların davranışlarını kontrolda saxlamağa kömək edir.
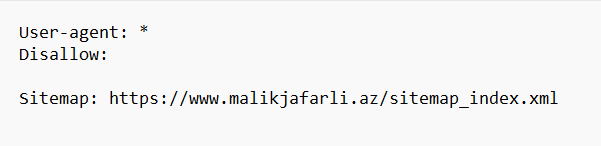
robots.txt faylının görünüşü aşağıdakı kimidir:
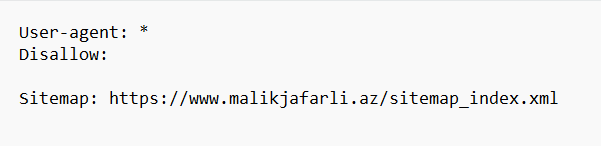
robots.txt faylı nə edir ?
Ümumiyyətlə müəyyən bir səhifənin ranklanması prosesi “crawling” ilə başlayır. Crawling isə botların veb-saytdakı linkləri izləməsi ilə baş verir. “A” adlı linki crawl edərək, “B” linkini kəşf edir, sonra “C” və.s. Ancaq botlar daha əvvəl qarşılaşmadığı bir domen adını crawl etmədən əvvəl robots.txt fayla baxır. Nəticədə hansı URL-lərə crawl edəcəyini və ya edəməcəyini anlamış olur.
robots.txt faylı hansı qayda da yerləşdirilməlidir ?
Bu fayl domenin “root”unda yerləşməlidir çünki botlar onu məhz orada axtarır. Əgər veb-saytınızın domen adı “www.example.com”dursa fayl www.example.com/robots.txt bu ünvanda yerləşdirilməlidir. Yəni:
Düzgün: https://www.example.com/robots.txt
Səhv: https://www.example.com/files/robots.txt
Səhv: https://www.example.com/subfolder/robots.txt
Fayl adına qarşıda həssasdır. Faylı əlavə edərkən adı “robots.txt” olmasına da diqqət edilməlidir əks-halda fayl öz funksiyasını yerinə yetirmir.
Düzgün: robots.txt
Səhv: Robots.txt
Səhv: ROBOTS.txt
Bu faylın veb-saytda əlavə edilməsinə gəldikdə bunun üçün YoastSEO, All in One SEO, RankMath kimi plugin-lərdən istifadə edə bilərsiniz.
robots.txt faylının strukturu
robots.txt faylının strukturu, bir və ya bir neçə directive blokundan ibarətdir. Hər blok müəyyən bot və ya bot qruplarına tətbiq olunan qaydaları özündə birləşdirir. Directive isə faylın içərisində yer alan müxtəlif təlimatların ümumi adıdır.cDirective-lərin ən geniş yayılmış tipi “User-agent” və “disallow”dur.
User-agent directive
Hər bir axtarış matorunun səhifəni “crawl” etmək üçün botlara sahib olduğu artıq məlumdur. Bu botların hər biri aid olduğu axtarış matoruna uyğun xüsusi ada sahibdir hansı ki, bu User-agent adlanır. User-agent, robots.txt faylının ilk sətrində duran directive-dir və müxtəlif botlara (və ya hamsına) edilən müraciətdir. Qısaca, user-agent görüləcək işlərin hansı bot və ya botlara aid olduğunu izah edir.
İstifadə qaydasına gəldikdə isə bütün botların veb-saytı “crawl” etməməsi və etməsi üçün faylın içərisində “User-agent”in qarşısına qoşa nöqtə qoyduqdan sonra “*” simvolu atmaq kifayət edir. robots.txt faylındakı məlumatların spesifik bota aid olmasını istəyirsinizsə onda həmin botun “user-agent” adını yazmalısınız.
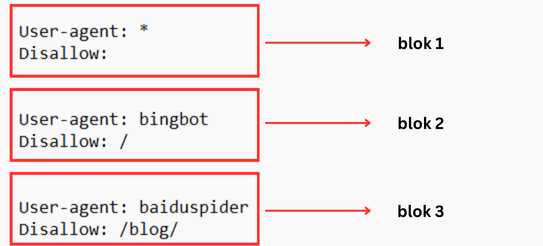
Bir çox axtarış matoru birdən çox bota malikdir. Məsələn, şəkillər üçün ayrıca bir bot, videolar üçün ayrıca bir bot və.s.
Botlar, robots.txt faylını oxuyarkən hər zaman daha spesifik olan blokuna üstünlük verirlər. Məsələn, əgər faylda üç blok mövcuddursa — biri * (bütün botlar) üçün, biri Googlebot üçün və digəri Googlebot-Video üçün — hər bot, öz user-agent adına ən çox uyğun gələn bloku izləyəcək.
Əgər Google-News botu robots.txt faylını skan edirsə və onun tam adı ilə uyğun blok mövcud deyilsə, bot Googlebot blokundakı qaydaları izləyəcək. Bunun səbəbi, botun adında “Google” sözü keçdiyi üçün və * blokundan daha spesifik olmasıdır. Digər tərəfdən, əgər Google-Video botu faylı yoxlayırsa, o zaman tam adı ilə uyğun gələn blokdakı qaydalara əməl edəcək.
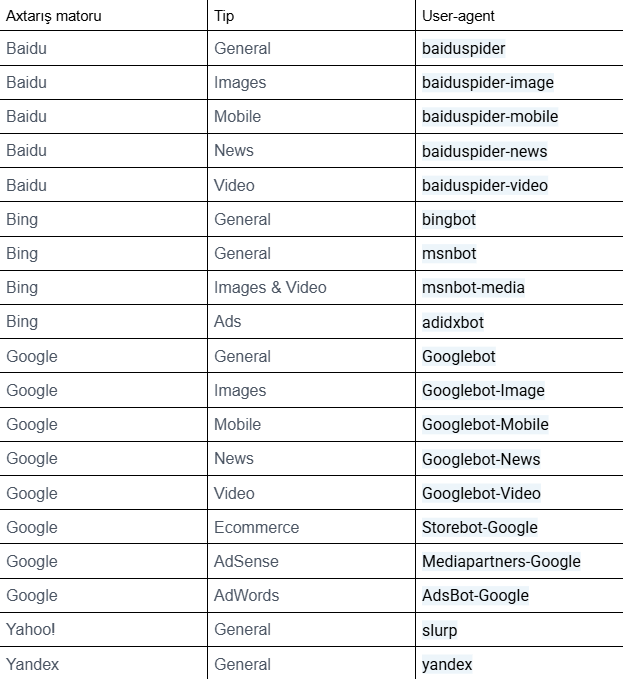
Ən çox istifadə edilən user-agent-lər siyahısı
Aşağıdakı cədvəldə ən çox istifadə edilən axtarış matorları botlarının user-agent-ləri haqqında məlumatı əhatə edir.
Disallow directive
İstənilən robots.txt faylında ikinci sətrdə adətən Disallow directive-i yerləşir. Disallow botun veb-saytın hansı hissələrinə daxil ola bilməyəcəyini göstərir. Həmçinin faylın ikinci, üçüncü və sonrakı sətirlərində bu directive-i təkrar əlavə edərək istifadə etmək mümkündür.
Əgər qoşa nöqtədən sonra Disallow directive-i boş buraxılarsa, bu, bot üçün heç bir məhdudiyyət olmadığı və veb-saytın istənilən hissəsinə daxil ola biləcəyi mənasına gəlir.

Aşağıdakı nümunədə isə disallow directive-i, bütün botların saytınızı crawl etməsinin qarşısını alır.

Bu nümunədə directive, Google-Video botunun /videos/ slug-u ilə başlayan bütün digər səhifələri və içərisindəki məlumatları crawl etməsinin qarşısını alır.

Bu, /video/ səhifəsi ilə yanaşı, onun daxilindəki bütün alt səhifələrin (məsələn, /video/2025-videos/) də crawl edilməyəcəyi mənasına gəlir. Bundan əlavə, əgər /videographers/ adlı səhifə mövcuddursa, onun botlar tərəfindən oxunmasının qarşısını alınacaq.
Qeyd edim ki, burada böyük-kiçik hərf fərqi nəzərə alınır. Məsələn, /videos/ əvəzinə /Videos/ yazsanız, botlar bunu tamamilə fərqli bir səhifə kimi qəbul edəcək. Buna görə də müvafiq səhifənin adını əlavə edərkən yazılışına diqqət edin.
Xüsusi simvollar necə istifadə edilir ?
robots.txt faylında müəyyən fayl qruplarını bloklamaq üçün “*” simvolundan istifadə edə bilərsiniz.

Bu blokun 2-ci sətrinə görə bütün botlar sonu “.png” ilə bitən heç bir şəkli crawl etməyəcək. 3-cü sətirə görə isə qalareya səhifəsində sonu “.jpg” ilə bitən heç bir şəkli crawl etməyəcək. Yuxarıda bəhs etdiyim böyük-kiçik hərf fərqi bura da aid olduğu üçün səhifə adı və fayl uzantılarını yazşılışına diqqət edin.
Bu üsul bir standart olmasına baxmayaraq bütün böyük axtarış matorları bu qayda ilə tərtib edilən faylları başa düşə bilir.
Qeyri-standart directive-lər
robots.txt fayllarında ən çox istifadə olunan Disallow və User-agent directive-lərinə əlavə olaraq, bir neçə başqa directive də mövcuddur. Bunlara “allow”, “sitemap”, “crawl-delay”, “allow” daxildir. Lakin nəzərə almaq lazımdır ki, bütün axtarış mühərriki botları bu directive-ləri dəstəkləmir. Buna görə onları tətbiq etməzdən istifadə qaydalarını yaxşı anlamaq vacibdir.
Allow directive
Çox istifadə edilməsə də bu directive əksər axtarış matoru botları tərəfindən başa düşülür.İşləmə qaydası isə disallow directive-nin əksi kimi botlara səhifəni crawl etməyə icazə verir.

Bu blok “/secure/request-ajax.php” istisna olmaqla “/secure/” və onun içərisindəki hər şeyi blokla və ya crawl etmə mənasına gəlir. “Allow” directive olmadan bu kimi istisnaların yaratmağın digər yolu isə “disallow” səhifələrin manual olaraq tək-tək əlavə edilməsidir.
Qeyd edim ki, robots.txt faylında hər iki directive-lərin (disallow və allow) case-sensitive deyil yəni, istər böyük hərflə başlasın, istər kiçik hərflə bu fərq etmir. Ancaq, onların qarşısında duran dəyərləri yuxarıda qeyd edildiyi kimi case-sensitive-dir.
Sitemap directive
Bu directive Google, Yandex, Bing kimi axtarış matorlarının botlarına veb-saytın XML Sitemap-nin harada yerləşdiyini bildirir. Sİtemap Google Search Console istifadəsi ilə də əlavə etmək mümkündür.
Crawl-delay directive
“Crawl-delay”, standarta daxil olmayan və Google, Yandex kimi axtarış matorlarının botlarının robots.txt faylını skan edərkən başa düşmədiyi bir directive tipidir.
Burada directive işləmə prinsipi botlarının hansı tezlikldə veb-saytınızı crawl etməsini bildirməkdir.

Bu bloka əsasən bu directive başa düşən botlar səhifəni crawl edərkən 15 saniyə aralığında fasilə verəcək hansı ki, bu gündə 5760 səhifə deməkdir. Bu kiçik veb-saytlar üçün çox olsa da, böyük veb-saytlar üçün azdır.
Son olaraq, fayl tam hazır olduqdan sonra Google Search Console-un “robots.txt tester” aləti ilə yoxlayın. Çünki test edilmədən robots.txt-nin veb-sayta əlavə edilməsi istənilməyən səhifələrin bloklanması ilə nəticələnə bilər.
Test etmək üçünGoogle Search Console-a daxil olaraq “>Settings>robots.txt” icra edin.